
Русские Блоги
Углубленная аппаратная архитектура и механизм работы графического процессора
1. Введение
Для большинства разработчиков графического рендеринга графический процессор является знакомым и незнакомым компонентом. Знакомо то, что с ним нужно иметь дело каждый день. Необычно то, что графический процессор похож на черный ящик. Я не знаю его внутренней аппаратной архитектуры, не говоря уже о его работе. механизм.
В этой статье, где NVIDIA является основным направлением деятельности, будет предпринята попытка всесторонне и глубоко проанализировать аппаратную архитектуру и рабочий механизм графического процессора.Она в основном включает графические процессоры настольного уровня на ПК и не будет охватывать графические процессоры на уровне мобильных, профессиональных вычислений и графических рабочих станций.
Чтобы прочитать эту статью, читатели должны иметь определенный фундамент в области графики и понимать конвейер рендеринга графического процессора.Лучше всего иметь написанный код шейдера, такой как HLSL и GLSL.
1.1 Почему я должен понимать GPU?
Понимая аппаратную архитектуру GPU и понимая механизм работы, автор полагает, что есть много преимуществ, и резюмирует их следующим образом:
- Изучите физическую структуру и механизм работы графического процессора. Графический процессор превращается из черного ящика в белое.
- Легче найти узкие места рендеринга и написать высокоэффективный шейдерный код.
- Идите в ногу с тенденциями времени и поймите передовые технологии рендеринга!
- Многие навыки не подавляют!
1.2 Основные моменты содержания
Основные положения этой статьи резюмируются следующим образом:
- Введение, история и характеристики GPU.
- Аппаратная архитектура GPU.
- Механизм согласованного планирования GPU и CPU.
- Структура кеш-памяти GPU.
- Конвейер рендеринга GPU.
- Рабочий механизм GPU.
- Методы оптимизации GPU.
1.3 Читать с вопросами
Чтение технических статей с соответствующими вопросами обычно может углубить понимание и память. При чтении этой статьи могут возникнуть следующие вопросы:
1. Как графический процессор взаимодействует с процессором?
2. Есть ли в GPU механизм кеширования? Сколько здесь этажей? Насколько у них разница в скорости?
3. Каковы этапы процесса рендеринга GPU? Каковы их функции?
4. Что такое технология Early-Z? На каком этапе это произошло? Что еще будет на этом этапе? В чем будет проблема? Как решить?
5. Что такое SIMD и SIMT? В чем их преимущества? А как насчет совместного выпуска?
6. Есть ли параллельная обработка на GPU? Если да, как спроектирован и реализован аппаратный уровень?
7. Что такое GPC, TPC, SM? Что такое деформация? Какая связь между ними и Core и Thread?
8. Могут ли вершинный шейдер (VS) и пиксельный шейдер (PS) быть одним и тем же процессором? Зачем?
9. Минимальная единица обработки пиксельного шейдера (PS) составляет 1 пиксель? Зачем? Какое влияние это окажет?
10. Снижают ли операторы if и for в шейдере эффективность рендеринга? Зачем?
11. Как показано на рисунке ниже, более эффективно визуализировать ту же область графики, количество треугольников меньше (слева) или количество треугольников (справа) больше? Зачем?

12. Что такое контекст графического процессора? какой эффект?
13. Каковы вероятные проблемы, вызывающие узкие места при рендеринге? Как их избежать или оптимизировать?
Если после прочтения этой статьи вы сможете очень четко ответить на все вышеперечисленные вопросы, то поздравляем с усвоением сути этой статьи!
Два, обзор графического процессора
2.1 Что такое графический процессор?
GPUПолное имяGraphics Processing Unit, Блок обработки графики. Его функция изначально соответствовала названию, и это была особая микросхема, предназначенная для рисования изображений и обработки метаданных изображений.Позже постепенно были добавлены многие другие функции.

Физическая карта чипа NVIDIA GPU。
Когда мы говорим о графических процессорах и видеокартах, мы часто их путаем, строго говоря, они разные. Графический процессор является основным компонентом видеокарты (видеокарта, видеокарта, видеокарта), но в дополнение к графическому процессору видеокарта также имеет тепловентилятор, компоненты связи и различные слоты для подключения к материнской плате и дисплею.
Для настольных ПК существует два основных производителя графических процессоров:
- NVIDIA: Nvidia — ведущий производитель графических процессоров на сегодняшний день. Продукты NVIDIA широко известны как карты N, представляющие такие продукты, как серии GeForce, GTX и RTX.

- AMD: Это производитель как процессора, так и графического процессора. Его графическая карта обычно известна как карта A. Типичные продукты включают серию Radeon.

Конечно, и NVIDIA, и AMD также производят графические процессоры для мобильных и графических рабочих станций. Кроме того, компании, производящие мобильные видеокарты, включают ARM, Imagination Technology и Qualcomm.
2.2 История GPU
Начиная с зародыша в 1990-х годах, GPU превратился не только в рендеринг графики, такой простой, как рендеринг графики, но и в такие функции, как математические вычисления, физическое моделирование и операции AI.
2.2.1 История развития NV GPU
Ниже приведена таблица узлов разработки GPU:

- 1995 – NV1Экран рендеринга NV1 и его характеристики.
- 1997 – Riva 128 (NV3), DX3
- 1998 – Riva TNT (NV4), DX5
- 32-битный цвет, 24-битный Z-буфер, 8-битный буфер шаблона
- Двойная текстура, билинейная фильтрация
- 2 пикселя за такт (2 ppc)
- 1999 — GeForce 256(NV10)
- Фиксированный трубопровод, Поддерживает DirectX 7.0
- Оборудование T&L(Преобразование и освещение, преобразование координат и освещение)
- Кубическая карта (Cubemaps)
- DOT3 – bump mapping
- 2-х кратная анизотропная фильтрация
- Трилинейная фильтрация
- Сжатие текстур DXT
- 4ppc
- Введите термин «GPU»

Экран рендеринга NV10 и его характеристики.
- DirectX 8.0
- Shader Model 1.0
- Программируемый конвейер рендеринга
- Вершинный шейдер
- Пиксельный шейдер

Экран рендеринга NV20 и его характеристики.
- DirectX 9.0
- Shader Model 2.0
- 256 инструкций по работе с вершинами
- 32 текстуры + 64 арифметических инструкции по работе с пикселями
- 256 инструкций по работе с вершинами
- Операционные инструкции 512 пикселей
- HLSL
- CGSL
- GLSL

Экран рендеринга NV30 и его характеристики.
- 2004-GeForce 6 серии (NV4x)
- DirectX 9.0c
- Shader Model 3.0
- Динамическое управление потоком
- Ветви, петли, объявления и т. Д.
- 64-битная текстура рендеринга (Render Target)
- FP16 * 4 фильтрация и смешивание текстур

Экран рендеринга NV40 и его характеристики.
- 2006-серия GeForce 8 (G8x)
- DirectX 10.0
- Shader Model 4.0
- Геометрические шейдеры
- Биты без колпачков
- Унифицированные шейдеры (Unified Shaders)

Рендеринг NV G80 и его характеристики.
- DirectX 11.0
- мозаика
- Шейдер корпуса
- Tessellator
- Шейдер домена
- Поддержка вывода потока

Конвейер рендеринга DirectX 11.
- Поддержка многопоточности
- Улучшено сжатие текстур
- Дополнительные инструкции, блоки памяти, регистры
- Объектно-ориентированный язык затенения
- мозаика
- Вычислить шейдер
- DirectX 12.0
- Легкий приводной слой
- Поддержка многопоточного рендеринга на аппаратном уровне
- Поддержка технологий RTX и DXR впервые, а именноПоддержка трассировки лучей
- Представляем RT Core (ядро трассировки лучей)

Список видеокарт, поддерживающих трассировку лучей RTX.

- 2018 — TITAN RTX(TU102)
- DirectX 12.1,OpenGL 4.5
- 6GPC,36TPC,72SM,72RT Core,.
- Разрешение 8K, основная частота 1770 МГц, видеопамять 24 ГБ, полоса пропускания 384 бит
Из вышесказанного видно, что оборудование графического процессора разрабатывается вместе со стандартами графического API и играми, и они сформировали благоприятные отношения, которые дополняют и продвигают друг друга.
2.2.2 История архитектуры NV GPU
Как мы все знаем, разработка CPU подчиняется закону Мура: скорость удваивается каждые 18 месяцев.

Количество транзисторов в процессоре соответствует закону Мура. Справа — сам Мур, основатель Intel.
И основатель NVIDIAХуан ЖэньсюньМного лет назад я поклялся сказать, что скорость и функции графического процессора должны превосходить закон Мура, удваиваясь каждые 6 месяцев. История разработки графических процессоров NV доказывает, что он это сделал! Скорость ускорения GPU намного превышает скорость CPU:

Архитектура NVIDIA GPU претерпела множество изменений.От первоначальной Tesla до новейшей архитектуры Turing история разработки может быть разделена на следующие временные узлы:
- 2008 — Tesla Первоначально Tesla использовалась для вычислительных процессоров и использовалась в первых сериях графических чипов CUDA, а не в обычных чипах обработки графики в истинном смысле этого слова.
- 2010 — Fermi Fermi — первая полноценная вычислительная архитектура на GPU. Первая архитектура графического процессора, которая может поддерживать чистую интеграцию на уровне кэша с общим хранилищем и поддерживает архитектуру графического процессора ECC.
- 2012 — Kepler Кеплер быстрее, эффективнее и эффективнее Ферми.
- 2014 — Maxwell Его новая технология воксельного глобального освещения (VXGI) позволяет игровым графическим процессорам впервые обеспечивать эффекты динамического глобального освещения в реальном времени. Графические процессоры GTX 980 и 970 на базе архитектуры Maxwell используют ряд новых технологий, включая сглаживание многокадровой выборки (MFAA), динамическое сверхвысокое разрешение (DSR), VR Direct и ультра-энергосберегающий дизайн.
- 2016 — Pascal Архитектура Pascal объединяет процессор и данные в одном пакете для достижения более высокой вычислительной эффективности. Серии 1080 и 1060 основаны на архитектуре Pascal.
- 2017 — Volta Volta оснащена 640 ядрами Tensor, которые могут выполнять более 100 триллионов операций с плавающей запятой (TFLOPS) в секунду при глубоком обучении, что более чем в 5 раз быстрее, чем в архитектуре Pascal предыдущего поколения.
- 2018 — Turing Архитектура Тьюринга оснащена специальным процессором трассировки лучей под названием RT Core, который может ускорять распространение света и звука в трехмерной среде со скоростью до 10 гига-лучей в секунду. Архитектура Тьюринга ускоряет операции трассировки лучей в реальном времени в 25 раз по сравнению с архитектурой NVIDIA Pascal ™ предыдущего поколения и может выполнять рендеринг финального кадра эффектов фильмов со скоростью, более чем в 30 раз превышающей скорость ЦП. Графические карты серии 2060 и 2080 также пропустили Volta и напрямую выбрали архитектуру Turing.
На следующем рисунке показана история разработки некоторых архитектур GPU:

2.3 Функции графического процессора
Помимо рисования графики, современные графические процессоры также выполняют множество дополнительных функций, которые можно резюмировать следующим образом:
- Графический рисунок. Это самый традиционный навык графического процессора, а также самая основная и основная функция. Предоставляет функции обработки графики и рисования для большинства настольных ПК, мобильных устройств и графических рабочих станций.
- Физическое моделирование. Физический движок, интегрированный в аппаратный графический процессор (PhysX, Havok), обеспечивает в сотни и тысячи раз более высокую производительность, чем физическое моделирование для игр, фильмов, образования, научного моделирования и других областей, обеспечивая имитацию физики в реальном времени, которая ранее требовала длительных расчетов.
- Расчет массы. Появление вычислительных шейдеров и потокового вывода выполнило множество огромных требований, которые можно вычислять параллельно, и CUDA является лучшим примером.
- Работа ИИ. В последние годы развитие искусственного интеллекта способствовало интеграции вычислительных блоков AI Core в графические процессоры, что способствовало повышению вычислительной мощности AI и предоставлению вычислительной мощности всем слоям населения.
- Прочие расчеты. Кодирование и декодирование аудио и видео, шифрование и дешифрование, научные вычисления, автономный рендеринг и т. Д. Неотделимы от возможностей параллельных вычислений и огромной пропускной способности современных графических процессоров.
Три, физическая архитектура графического процессора
3.1 Макро-физическая структура графического процессора
Благодаря внедрению нанотехнологий, GPU может интегрировать сотни миллионов транзисторов и электронных устройств в небольшой чип. Судя по макрофизической структуре, большинство современных графических процессоров для настольных ПК имеют размер, равный нескольким монетам, а некоторые даже меньше, чем монета (на фото ниже).

Чип дисплея Qualcomm Snapdragon 853 меньше монеты
Когда графический процессор объединен с охлаждающим вентилятором, слотом PCI, интерфейсом HDMI и другими компонентами, он образует видеокарту (на фото ниже).
Графическая карта не может работать независимо и должна быть загружена на материнскую плату в сочетании с аппаратными устройствами, такими как ЦП, память, видеопамять и дисплей, чтобы сформировать полноценный ПК.

Материнская плата с видеокартой.
3.2 Микрофизическая структура графического процессора
Микроструктура графического процессора варьируется от производителя к производителю и от архитектуры, но основные компоненты, концепции и рабочие механизмы схожи. Микрофизическая структура графических процессоров некоторых архитектур будет показана ниже.
3.2.1 Архитектура NVidia Tesla

Обзор микроархитектуры Tesla показан выше. Его характеристики и концепции будут объяснены ниже:
- 7 групп TPC (кластер текстуры / процессора, кластер обработки текстур)
- Каждый TPC имеет два набора SM (Stream Multiprocessor).
- Каждый SM содержит:
- 6 SP (потоковый процессор)
- 2 SFU (блок специальных функций, блок специальных функций)
- Кэш L1, проблема MT (получение многопоточных инструкций), C-Cache (постоянный кеш), общая память
3.2.2 Архитектура NVidia Fermi

Архитектура Fermi показана на рисунке выше, и ее особенности следующие:
- Есть 16 см
- Каждый SM:
- 2 Warp (деформация)
- Всего 32 ядра в двух группах
- 16 групп единиц хранения нагрузки (LD / ST)
- 4 блока специальных функций (SFU)
- 16 ядер
- Планировщик деформации
- Группа отправки
- 1 FPU (блок с плавающей запятой)
- 1 ALU (логическая операционная единица)
3.2.3 Архитектура NVidia Maxwell

Используя GM204 Maxwell, он имеет 4 GPC, а каждый GPC имеет 4 SM.По сравнению с архитектурой Tesla, процессор был значительно улучшен.
3.2.4 Архитектура NVidia Kepler

В дополнение к аппаратным улучшениям и большему количеству процессоров, Кеплер также обновил SM до SMX. SMX — это улучшенная архитектура, которая поддерживает динамическое создание потоков рендеринга (ниже) для уменьшения задержки.

3.2.5 Архитектура NVidia Turing

На картинке выше изображен графический процессор TU102 с архитектурой Turing со следующими характеристиками:
- 6 GPC (кластер обработки графики)
- 36 TPC (Кластер обработки текстур)
- 72 SM (потоковый мультипроцессор)
- Каждый GPC имеет 6 TPC, и каждый TPC имеет 2 SM.
- 4608 ядер CUDA
- 72 ядра RT
- 576 Тензорных ядер
- 288 текстурных блоков
- 12×32-битный контроллер памяти GDDR6 (всего 384 бит)
Структура единого СМ выглядит следующим образом:

Каждый SM содержит:
- 64 ядра CUDA
- 8 Тензорное ядро
- Регистровый файл 256 КБ
Физический образ микросхемы GPU TU102:

3.3 Общность архитектуры GPU
Глядя на все архитектуры GPU в предыдущем разделе, мы можем обнаружить, что, хотя они разные, есть много похожих концепций и компонентов:
- GPC
- TPC
- Thread
- SM、SMX、SMM
- Warp
- SP
- Core
- ALU
- FPU
- SFU
- ROP
- Load/Store Unit
- L1 Cache
- L2 Cache
- Memory
- Register File
Назначение каждого из вышеперечисленных компонентов будет подробно объяснено в следующей главе.
Почему у графического процессора так много уровней и так много похожих частей? Ответ заключается в том, что задачи графического процессора естественно параллельны, и все современные архитектуры графических процессоров рассчитаны на высокий параллелизм.
В-четвертых, рабочий механизм GPU
4.1 Обзор рендеринга на GPU
Из предыдущей главы мы видим, что современные графические процессоры имеют похожие структуры, многие из одинаковых компонентов и много общих точек в операционных механизмах. Ниже представлена обзорная диаграмма рабочего механизма архитектуры Fermi:

Начиная с Fermi, NVIDIA использует аналогичную принципиальную архитектуру, используя Giga Thread Engine для управления всей текущей работой, графический процессор разделен на несколько GPC (кластер обработки графики), каждый GPC имеет несколько SM (SMX, SMM) и один Raster Engine, у них много соединений, наиболее примечательным является Crossbar, который может подключать GPC и другие функциональные модули (такие как ROP или другие подсистемы).
Шейдер, написанный программистом, сделан на SM. Каждый SM содержит множество ядер, которые выполняют математические операции с потоками. Например, поток может быть вызовом вершинного или пиксельного шейдера. Эти ядра и другие блоки управляются Warp Scheduler, который управляет группой из 32 потоков как Warp (деформация) и передает инструкции, которые должны быть выполнены, в Dispatch Units.
Фактическое количество этих блоков в GPU (сколько SM на GPC, сколько GPC . ) зависит от самой конфигурации чипа. Например, GM204 имеет 4 GPC, и каждый GPC имеет 4 SM, но Tegra X1 имеет 1 GPC и 2 SM, оба из которых разработаны Максвеллом. Сам дизайн SM (количество ядер, блоки команд, планировщик . ) также изменился с течением времени и помог сделать чип настолько эффективным, что его можно расширить с настольных компьютеров высокого класса до мобильных ноутбуков.

Как показано на рисунке выше, для одного SM некоторых графических процессоров (например, некоторых моделей Fermi) он содержит:
- 32 вычислительных ядра (Core, также называемый потоковым процессором)
- 16 модулей LD / ST (загрузка / сохранение) для загрузки и хранения данных
- 4 SFU (блоки специальных функций) для выполнения специальных математических операций (sin, cos, log и т. Д.)
- 128 КБ регистр (регистровый файл)
- Кэш L1 64 КБ
- Кэш глобальной памяти (Uniform Cache)
- Блок чтения текстур
- Кэш текстур
- Механизм PolyMorph: Механизм многоугольника отвечает за настройку атрибутов, VertexFetch, тесселяцию и растеризацию (этот модуль может понимать вещи, которые имеют дело конкретно с вершинами).
- 2 планировщика деформации: этот модуль отвечает за планирование деформации. Деформация состоит из 32 потоков. Инструкции планировщика деформации отправляются в ядро для выполнения через блоки диспетчеризации.
- Кэш инструкций
- Межсетевое соединение
4.2 логический конвейер GPU
После понимания компонентов и концепций, описанных в предыдущем разделе, вы можете более подробно остановиться на процессе и этапах рендеринга графического процессора. Ниже приводится пример SM семейства Ферми для подробного описания логического конвейера.

1. Программа отправляет инструкцию отрисовки через графический API (DX, GL, WEBGL), инструкция будет передана драйверу, драйвер проверит ее законность, а затем поместит инструкцию в Pushbuffer, который может прочитать графический процессор.
2. По прошествии определенного периода времени или после явного вызова команды flush драйвер отправляет содержимое Pushbuffer на GPU, который получает эти команды через Host-интерфейс и обрабатывает эти команды через Front End.
3. Запустите распределение работы в Primitive Distributor, обработайте вершины в индексном буфере, чтобы сгенерировать треугольники в пакеты, а затем отправить их нескольким PGC. Смысл этого шага состоит в том, чтобы отправить n треугольников и назначить их этим PGC для одновременной обработки.

4. В GPC Poly Morph Engine в каждом SM отвечает за выборку данных вершин через индексы треугольников, то есть модуль Vertex Fetch на рисунке.
5. После получения данных в SM планируется деформация с 32 потоками в качестве группы для начала обработки данных вершин. Деформация — это типичная реализация многопоточности с одной инструкцией (SIMT, SIMD, обновление нескольких данных с одной инструкцией), то есть инструкции, выполняемые одновременно 32 потоками, точно такие же, но данные потоков разные.Преимущество этого состоит в том, что требуется только одна деформация. Набор логики декодирует и выполняет инструкции.Чип можно сделать меньше и быстрее.Причина в том, что задачи, которые должен обрабатывать графический процессор, естественно параллельны.
6. Планировщик деформации SM будет распределять инструкции по всей основе по порядку. Потоки в одной основе будут блокировать шаг для выполнения своих соответствующих инструкций. Если поток обнаруживает неактивное выполнение, он также будет замаскирован (замаскирован). вне). Есть много причин для того, чтобы быть скрытым. Например, текущая инструкция является ветвью if (true), но условие данных текущего потока ложно, или количество циклов другое (например, количество циклов for n не является постоянным, или оно преждевременно прерывается прерыванием Но другие вещи все еще продолжаются), поэтому ветвь в шейдере значительно увеличит потребление времени, ветвь в деформации, если только 32 потока не находятся в if или else, это эквивалентно всем проходящим ветвям, thread Команды не могут выполняться независимо, кроме деформации, и эти деформации независимы.
7. Инструкции в деформации могут быть выполнены одновременно или могут быть запланированы несколько раз.Например, обычно количество модулей LD / ST (доступ к нагрузке) в SM значительно меньше, чем количество основных математических операций.
8. Поскольку выполнение некоторых инструкций занимает больше времени, чем других, особенно загрузка памяти, планировщик деформации может просто переключиться на другую деформацию без ожидания памяти. Это ключ к тому, как графический процессор преодолевает задержку чтения из памяти. , Просто переключите активную группу потоков. Чтобы сделать это переключение очень быстрым, все деформации, управляемые планировщиком, имеют свои собственные регистры в файле регистров. Здесь будет противоречие. Чем больше регистров потребуется шейдеру, тем меньше места будет оставлено для деформации и тем меньше будет генерироваться деформация. В это время, когда есть задержка памяти, он будет просто ждать, а не ничего. Поворот, который можно запустить, можно переключать.

9. Как только деформация выполнит все инструкции вершинного шейдера, результат вычисления будет обработан модулем преобразования видового экрана, треугольник будет обрезан и затем готов для растеризации, а графический процессор будет использовать кеши L1 и L2 для данных вершинного шейдера и пиксельного шейдера. Связь.

10. Затем эти треугольники будут разделены и назначены нескольким GPC. Диапазон треугольника определяет, каким растровым движкам он будет назначен. Каждый растровый движок покрывает несколько листов на экране, что эквивалентно Распределите визуализацию треугольника на несколько плиток. То есть этап пикселей меняет деление по треугольникам на деление по отображаемым пикселям.

11. Настройка атрибутов на SM гарантирует, что данные из вершинного шейдера будут читаться с помощью затенения пикселей после интерполяции.
12. Растровые механизмы в GPC работают с треугольниками, которые он получает, чтобы генерировать информацию о пикселях этих треугольников (он также обрабатывает отсечение, отсечение обратной стороны и отсечение Early-Z).
13. 32-пиксельные потоки будут разделены на группу или 8 блоков размером 2×2 пикселя. Это наименьшая единица работы пиксельного шейдера. В этом пиксельном потоке, если он не покрыт треугольником, он будет скрыт. SM Планировщик деформации будет управлять задачами пиксельного шейдера.
14. Следующий этап точно такой же, как и логические шаги в вершинном шейдере, но он выполняется в потоке пиксельного шейдера. Поскольку для получения значения в пикселе не требуется никакой производительности, выполнение блокировки очень удобно, и все потоки могут гарантировать, что все инструкции могут быть в одной точке.

15. Последний шаг, теперь, когда пиксельный шейдер завершил расчет цвета и вычисление значения глубины, на этом этапе мы должны рассмотреть исходный порядок api треугольников перед передачей данных в ROP (модуль вывода визуализации, ввод ввода Unit). Внутри ROP есть много блоков ROP. Тест глубины обрабатывается в блоке ROP, а буфер кадра смешивается. Параметры глубины и цвета должны быть атомарными операциями, иначе два разных треугольника будут конфликтовать и находиться в одном пикселе. ошибка.
4.3 Технические особенности GPU
Поскольку в предыдущем разделе в основном объяснялся внутренний рабочий процесс и механизм графического процессора, многие точки знаний и процессы были опущены для простоты. В этом разделе они будут более подробно описаны.
4.3.1 SIMD и SIMT
SIMD(Single Instruction Multiple Data) — одна инструкция и несколько данных В блоке ALU графического процессора одна инструкция может обрабатывать многомерные векторные (обычно 4D) данные. Например, есть следующие команды шейдера:
float4 c = a + b; // a и b относятся к типам float4Для процессора без SIMD необходимы 4 инструкции для добавления 4 значений с плавающей запятой. Псевдокод ассемблера выглядит следующим образом:
ADD c.x, a.x, b.x ADD c.y, a.y, b.y ADD c.z, a.z, b.z ADD c.w, a.w, b.wНо с технологией SIMD может быть обработана только одна инструкция:
SIMD_ADD c, a, b
SIMT(Single Instruction Multiple Threads) — это обновленная версия SIMD, которая может одновременно обрабатывать одну и ту же инструкцию для нескольких ядер в одном SM в графическом процессоре, и данные, к которым обращается каждое ядро, могут быть разными.
SIMT_ADD c, a, bВышеуказанные инструкции будут отправлены всем Ядрам, сгруппированным в один SM одновременно, и расчет будет выполняться одновременно, но a 、 b 、 c Значение может быть разным:

4.3.2 co-issue
co-issueЭто должно решить проблему, заключающуюся в том, что вычислительный блок SIMD не может быть использован полностью. Например, на рисунке ниже из-за разницы в количестве флотов коэффициент использования ALU снижается со 100% до 75%, 50% и 25%.

Чтобы решить проблему низкого использования шейдера в векторах низкой размерности, можно комбинировать 1D и 3D или 2D и 2D инструкции. Например, на следующем рисунке, DP3 В инструкции используются 3D-данные, ADD Инструкции имеют только одномерные данные, и совместная выдача автоматически объединит их.Для завершения выполнения в том же ALU требуется всего один цикл команд.

Однако для Vector ALU, если одна из переменных является одновременно операндом и номером хранилища, технология совместной выдачи не может быть включена:

затемСкалярный шейдер инструкций(Scalar Instruction Shader), он может эффективно комбинировать любой вектор, открывать технологию совместной выдачи и в полной мере использовать преимущества SIMD.
4.3.3 оператор if-else

Как показано выше, в SM 8 ALU (Core). Из-за характеристик SIMD данные каждого ALU различны, в результате if-else Оператор, выполняемый в некотором ALU, выглядит так: true Ветвь (желтая), некоторые ALU работают false Ветвление (серо-синий), которое приводит к потере большого количества циклов выполнения ALU (то есть маскируется), что удлиняет весь цикл выполнения. В худшем случае коэффициент использования одного и того же SM составляет всего 1/8 (8 — это количество потоков одного и того же SM, а графические процессоры разных архитектур различаются).
тем же, for Циклы также могут приводить к аналогичным ситуациям, например к следующему коду шейдера:
void func(int count, int breakNum) < for(int i=0; i>Поскольку каждый ALU count Не то же самое, плюс break Ветвление, приводящее к самому быстрому завершению шейдерного ALU, может быть самым медленным в одну N-ю часть времени, но из-за характеристик SIMD самому быстрому ALU все равно приходится ждать завершения самого медленного ALU, прежде чем он сможет принять следующий набор инструкций. жить! Было потрачено много времени.
4.3.4 Early-Z
Тест глубины раннего конвейера рендеринга графического процессора выполнялся после пиксельного шейдера (см. Ниже), что заставляло многие невидимые пиксели выполнять требовательные к производительности вычисления пиксельного шейдера.

Позже, чтобы уменьшить дополнительное потребление пиксельного шейдера, тест глубины был перенесен перед пиксельным шейдером (ниже), который является источником технологии Early-Z.

Технология Early-Z может заранее удалить многие недопустимые пиксели, предотвращая их попадание в трудоемкий пиксельный шейдер. Самая маленькая единица отсечения Early-Z — не 1 пиксель, аБлок пикселей(Pixel quad, 2×2 пикселя, см.4.3.6)。
Однако следующие условия приведут к сбою Early-Z:
- Открытый альфа-тест: Поскольку альфа-тест необходимо сравнивать на этапе альфа-теста после пиксельного шейдера, невозможно определить, отбирается ли пиксель до пиксельного шейдера.
- Включите Alpha Blend: Многие пиксели с включенным альфа-смешиванием необходимо смешать с кадровым буфером, поэтому невозможно выполнить проверку глубины и использовать технологию Early-Z.
- Включите Tex Kill: То есть в коде шейдера есть инструкция сброса пикселей (сброс DX, клип OpenGL).
- Отключить тест глубины, Early-Z основан на условии, что тест глубины включен. Если тест глубины выключен, технология Early-Z не может быть включена.
- Включите мультисэмплинг: Множественная выборка повлияет на окружающие пиксели, и на этапе Early-Z не может быть известно, обрезаны ли окружающие пиксели, поэтому его нельзя удалить заранее.
- И любые другие операции, вызывающие необходимость смешивания цветов позади.
Кроме того, технология Early-Z может вызвать проблемы:Конфликт глубоких данных(depth data hazard)。

Пример следует объединить с приведенным выше рисунком. Предположим, что значение глубины 5 прошло Early-Z и будет записано в буфер кадра, а значение глубины 10 находится как раз на этапе Early-Z. Прочтите и сравните текущее значение глубины буфера 15, и в результате 10 прошло раньше. Тест -Z будет охватывать значение глубины 5, которое меньше его самого, и окончательное значение глубины буфера кадра является неправильным результатом.
Один из способов избежать конфликтов данных глубины — сравнить значение буфера кадра со значением буфера кадра перед записью значения глубины:

4.3.5 Унифицированная шейдерная архитектура
В ранних GPU аппаратная структура вершинного шейдера и пиксельного шейдера была независимой, и каждый имел свои собственные регистры, арифметические блоки и другие компоненты. Во многих случаях это вызовет дисбаланс задач между вершинным шейдером и пиксельным шейдером. Для задач с большим количеством вершин у пиксельного шейдера есть много состояний ожидания; для задач с большим количеством пикселей вершинный шейдер имеет много состояний ожидания (рисунок ниже).

Поэтому для устранения дисбаланса между VS и PS была введена унифицированная шейдерная архитектура (Unified Shader Architecture). С графическим процессором этой архитектуры VS и PS используют одно и то же ядро. То есть одно и то же Core может быть как VS, так и PS.

Это решает проблему дисбаланса между различными типами шейдеров, а также может уменьшить количество аппаратных блоков графического процессора, уменьшить физический размер и энергопотребление. Кроме того, VS и PS также могут быть объединены с другими шейдерами (геометрия, поверхность, расчет).

4.3.6 Quad пикселей
Шаг 13, упомянутый в предыдущем разделе:
32 пиксельных потока будут разделены на группу, или 8Блок 2×2 пикселей, Это наНаименьшая единица работы над пиксельным шейдеромВ этом пиксельном потоке, если он не покрыт треугольниками, он будет скрыт.Планировщик деформации в SM будет управлять задачей пиксельного шейдера.
Другими словами, в пиксельном шейдере четыре соседних пикселя рассматриваются как неразделимая группа и отправляются на 4 разных ядра в одном SM.
Почему самая маленькая единица, обрабатываемая пиксельным шейдером, представляет собой блок пикселей 2×2?
Автор рассуждает по следующим причинам:
1. Упростите и ускорите работу по назначению пикселей.
2. Оптимизируйте архитектуру SM и уменьшите количество и размер аппаратных единиц.
3. Уменьшите энергопотребление и улучшите коэффициент полезного действия.
4. Хотя результат недопустимых пикселей не будет сохранен, он может помочь функции получения эффективных пикселей. Видеть4.6 Использование расширенных примеров。
Хотя эта конструкция имеет свои преимущества, но в то же время она также усугубит ситуацию Over Draw и потеряет дополнительную производительность. Например, на рисунке ниже белый треугольник занимает только 3 пикселя (зеленый). Согласно нашим обычным представлениям, для отрисовки 3 раза требуется всего 3 ядра.

Однако, поскольку указанные выше 3 пикселя занимают разные блоки пикселей (разделены оранжевым), на самом деле для отрисовки 12 раз требуется 12 ядер (см. Ниже).

Это потребует дополнительных 300% производительности оборудования, что приведет к более серьезной ситуации перерасхода.
Для получения более подробной информации вы можете посмотреть официальное обучающее видео Unreal:Углубленное исследование рендеринга в реальном времени。
4.4 механизм ресурсов GPU
В этом разделе объясняется доступ к памяти графического процессора, управление ресурсами и другие механизмы.
4.4.1 Архитектура памяти
Часть архитектуры GPU похожа на CPU, а также имеет многоуровневую структуру кеш-памяти: регистры, кэш L1, кэш L2, видеопамять GPU, системная видеопамять.

Их скорость доступа последовательно снижается от регистров к системной памяти:
Тип хранилища регистр Общая память Кэш L1 Кэш L2 Текстура, постоянный кеш Глобальная память Цикл посещения 1 1~32 1~32 32~64 400~600 400~600 Видно, что шейдер напрямую обращается к регистрам, кэшам L1 и L2, но он очень медленно получает доступ к текстурам, кэшам констант и глобальной памяти, что вызывает большую задержку.
Вышеупомянутая многоуровневая структура кэша может быть названа «CPU-Style», также существует архитектура памяти в стиле GPU:

Эта архитектура характеризуется несколькими ALU, несколькими контекстами графического процессора, высокой пропускной способностью и полагается на высокую пропускную способность для обмена данными с системной памятью.
4.4.2 Контекст и задержка графического процессора
Из-за внедрения технологии SIMT многие ядра в одном SM не являются независимыми. Когда некоторым из них требуется доступ к текстурам, постоянным кэшам и глобальной памяти, это приведет к очень большим задержкам.
Например, на рисунке ниже представлено 4 набора контекста (Context), они используют один и тот же набор арифметических устройств ALU.

Предполагая, что первой группе контекста требуется доступ к кеш-памяти или памяти, что вызовет задержку от 2 до 3 циклов, планировщик активирует вторую группу контекста для использования ALU:

Когда вторая группа контекста обращается к кешу или память застревает, третья и четвертая группы контекста будут активированы по очереди, пока первая группа контекста не возобновит работу или все они не будут активированы:

Следствием задержки является то, что общее время выполнения каждой группы контекста увеличивается:

Однако чем больше контекста доступно, тем больше может быть улучшена пропускная способность вычислительного блока.Например, архитектура из 18 наборов контекста на следующем рисунке может максимизировать пропускную способность:

4.4.3 Гетерогенная система CPU-GPU
В зависимости от того, разделяют ли ЦП и ГП память, существует два типа архитектур ЦП-ГП:

СлеваОтдельная архитектура, CPU и GPU имеют независимые кэш и память, и они обмениваются данными через такие шины, как PCI-e. Недостатком этой структуры является то, что PCI-e имеет низкую полосу пропускания и большую задержку по сравнению с двумя, а передача данных стала узким местом в производительности. В настоящее время он широко используется, например, в ПК, смартфонах и т. Д.
СправаПарная архитектура, CPU и GPU совместно используют память и кеш. APU AMD использует эту структуру и в настоящее время в основном используется в игровых консолях, таких как PS4.
Что касается управления хранилищем, то в разделенной структуре ЦП и ГП имеют независимую память, и оба совместно используют набор виртуального адресного пространства, и при необходимости выполняется копирование памяти. Для связанной структуры графический процессор не имеет независимой памяти и разделяет системную память с графическим процессором, а MMU выполняет управление хранением.
4.4.4 Модель управления ресурсами GPU
На следующем рисунке представлена модель управления ресурсами отдельной архитектуры:

- MMIO(Memory Mapped IO)
- Связь между CPU и GPU осуществляется через MMIO. CPU получает доступ к статусу регистра GPU через MMIO.
- DMA передает большой объем данных посредством командного управления через MMIO.
- Порт ввода-вывода может использоваться для косвенного доступа к области MMIO, а программное обеспечение с открытым исходным кодом, такое как Nouveau, никогда не обращается к нему.
- Контекст GPU представляет состояние вычислений на GPU.
- Иметь собственный виртуальный адрес в GPU.
- В графическом процессоре могут сосуществовать несколько активных контекстов.
- ЦП выдает любую команду.
- Командный поток передается в аппаратный блок, которым является канал графического процессора.
- Каждый канал графического процессора связан с контекстом, а контекст графического процессора может иметь несколько каналов графического процессора.
- Каждый контекст графического процессора содержит дескрипторы канала графического процессора связанного канала, и каждый дескриптор является объектом в памяти графического процессора.
- Каждый дескриптор канала GPU хранит настройки канала, включая таблицу страниц.
- Каждый канал графического процессора выделяет уникальный командный буфер в памяти графического процессора, который виден процессору через MMIO.
- Как переключение контекста графического процессора, так и выполнение команд запланированы внутри аппаратного обеспечения графического процессора.
- Контекст GPU изолирован от других контекстов таблицей страниц в виртуальном базовом пространстве.
- Таблица страниц графического процессора изолирует таблицу страниц процессора и находится в памяти графического процессора.
- Физический адрес таблицы страниц графического процессора находится в дескрипторе канала графического процессора.
- Таблица страниц графического процессора не только преобразует виртуальные адреса графического процессора в физические адреса памяти графического процессора, но также и в физические адреса процессора. Таким образом, таблица страниц графического процессора может объединить виртуальный адрес графического процессора и адрес памяти процессора в единое виртуальное адресное пространство графического процессора.
- Устройство GPU подключается к хосту через шину PCI-e. Регистры базового адреса (BAR) — это окно MMIO, которое настраивается при запуске графического процессора.
- Регистры управления и память графического процессора отображаются в BAR.
- Память устройства GPU настраивает GPU и обращается к памяти GPU через отображаемое окно MMIO.
- PFIFO — это специальный компонент для отправки команд графического процессора.
- PFIFO поддерживает несколько независимых очередей команд, которые являются каналами.
- Эта очередь команд представляет собой кольцевой буфер с указателями на PUT и GET.
- Все инструкции выполнения, которые обращаются к области управления каналом, перехватываются PFIFO.
- Драйвер графического процессора использует дескриптор канала для хранения связанных настроек канала.
- PFIFO пересылает команду чтения в PGRAPH Engine.
Nouveau — это бесплатный драйвер видеокарты с открытым исходным кодом, написанный для видеокарт NVidia. Gdev — это богатый набор программного обеспечения с открытым исходным кодом для технологии NVIDIA GPGPU, включая драйверы устройств.
4.4.5 Поток данных CPU-GPU
На следующем рисунке представлена блок-схема данных CPU-GPU отдельной архитектуры:
1. Скопируйте обработанные данные из основной памяти в видеопамять.
2. Инструкция CPU управляет GPU.
3. Каждый арифметический блок в GPU обрабатывается параллельно. Этот шаг будет обращаться к данным из видеопамяти.
4. Графический процессор передает результат видеопамяти обратно в основную память.
4.4.6 Механизм визуализации
- Сигнал горизонтальной и вертикальной синхронизации В ранних ЭЛТ-мониторах электронная пушка сканировалась построчно сверху вниз, и на дисплее отображался кадр после сканирования. Затем электронная пушка возвращается в исходное положение для следующего сканирования. Чтобы синхронизировать процесс отображения дисплея с видеоконтроллером системы, дисплей использует аппаратные часы для генерации серии сигналов синхронизации.
 Когда электронная пушка меняет строки для сканирования, дисплей отправляет сигнал горизонтальной синхронизации (сокращенно горизонтальной синхронизации).HSync Когда рисование кадра завершено, электронная пушка возвращается в исходное положение, и перед подготовкой к рисованию следующего кадра дисплей отправит сигнал вертикальной синхронизации (для краткости вертикальной синхронизации).VSync。 Дисплей обычно обновляется с фиксированной частотой. Эта частота обновления — это частота, генерируемая сигналом VSync. Хотя современные дисплеи в основном представляют собой жидкокристаллические дисплеи, принципы в основном те же. ЦП отправляет вычисленное содержимое дисплея в ГП. После завершения рендеринга ГП результат рендеринга сохраняется в буфере кадров. Видеоконтроллер считывает данные в буфере кадров кадр за кадром в соответствии с сигналом VSync. После преобразования данных они, наконец, отображаются на мониторе.
Когда электронная пушка меняет строки для сканирования, дисплей отправляет сигнал горизонтальной синхронизации (сокращенно горизонтальной синхронизации).HSync Когда рисование кадра завершено, электронная пушка возвращается в исходное положение, и перед подготовкой к рисованию следующего кадра дисплей отправит сигнал вертикальной синхронизации (для краткости вертикальной синхронизации).VSync。 Дисплей обычно обновляется с фиксированной частотой. Эта частота обновления — это частота, генерируемая сигналом VSync. Хотя современные дисплеи в основном представляют собой жидкокристаллические дисплеи, принципы в основном те же. ЦП отправляет вычисленное содержимое дисплея в ГП. После завершения рендеринга ГП результат рендеринга сохраняется в буфере кадров. Видеоконтроллер считывает данные в буфере кадров кадр за кадром в соответствии с сигналом VSync. После преобразования данных они, наконец, отображаются на мониторе. 
- Двойная буферизация При однократной буферизации и чтение, и обновление буфера кадров будут иметь относительно большие проблемы с эффективностью, и часто будут случаи взаимного ожидания, что приведет к падению частоты кадров. Для решения проблемы эффективности GPU обычно вводит два буфера, а именноМеханизм двойной буферизации, В этом случае графический процессор предварительно отрендерит кадр в буфер для чтения видеоконтроллером. При рендеринге следующего кадра графический процессор будет напрямую указывать указатель видеоконтроллера на второй буфер.

- Вертикальная синхронизация Хотя двойная буферизация может решить проблему эффективности, она создаст новую проблему. Когда видеоконтроллер не закончил считывание, то есть когда содержимое экрана отображается наполовину, графический процессор отправляет новый кадр содержимого в буфер кадра и меняет два буфера, а видеоконтроллер передает новый кадр в буфер кадра. На экране отображается нижняя половина данных кадра, вызывая разрыв экрана:
 Для решения этой проблемы в GPU обычно есть механизм, называемыйВертикальная синхронизация(Аббревиатура также называется V-Sync.) Когда вертикальная синхронизация включена, графический процессор будет ждать отправки сигнала VSync дисплея перед выполнением рендеринга нового кадра и обновления буфера. Это может решить проблему разрыва изображения на экране и повысить его плавность, но для этого потребуется больше вычислительных ресурсов, а также возникнут некоторые задержки.
Для решения этой проблемы в GPU обычно есть механизм, называемыйВертикальная синхронизация(Аббревиатура также называется V-Sync.) Когда вертикальная синхронизация включена, графический процессор будет ждать отправки сигнала VSync дисплея перед выполнением рендеринга нового кадра и обновления буфера. Это может решить проблему разрыва изображения на экране и повысить его плавность, но для этого потребуется больше вычислительных ресурсов, а также возникнут некоторые задержки.
4.5 Рабочий механизм шейдера
Код шейдера также похож на традиционный C ++ и другие языки. Ориентированные на человека языки высокого уровня (GLSL, HLSL, CGSL) необходимо преобразовать в машинно-ориентированные двоичные инструкции с помощью компилятора. Двоичные инструкции могут быть переведены в код сборки, чтобы технический персонал мог обращаться к ним и отладки.

Процесс компиляции в инструкции сборки из языка высокого уровня обычно выполняется в автономной фазе, чтобы уменьшить потребление времени выполнения.
На этапе выполнения сторона ЦП передает двоичные инструкции шейдера на сторону ГП через PCI-e. Когда ГП выполняет код, он использует контекст для разделения инструкций на несколько каналов и передачи их в пространство хранения каждого ядра.
Для современных графических процессоров появляется все больше и больше программируемых этапов, включая, помимо прочего: вершинный шейдер, шейдер управления тесселяцией, шейдер геометрии, пиксель / Фрагментный шейдер, вычислительный шейдер, .

Эти шейдеры образуют конвейерный конвейер параллельного рендеринга. Следующее будет объяснено на конкретных примерах.
Следующий абзац представляет собой классический код для расчета диффузного отражения:
sampler mySamp; Texture2D myTex; float3 lightDir; float4 diffuseShader(float3 norm, float2 uv)
После компиляции он становится ассемблерным кодом:
: sample r0, v4, t0, s0 mul r3, v0, cb0[0] madd r3, v1, cb0[1], r3 madd r3, v2, cb0[2], r3 clmp r3, r3, l(0.0), l(1.0) mul o0, r0, r3 mul o1, r1, r3 mul o2, r2, r3 mov o3, l(1.0)На этапе выполнения вышеуказанный код сборки будет помещен в контекст выполнения графическим процессором, а затем ALU получит (Detch), декодирует (декодирует) инструкции сборки одну за другой и выполнит их.

На приведенной выше диаграмме в качестве примера показано выполнение только одного ALU. Фактически, GPU имеет десятки или даже сотни исполнительных блоков, выполняющих инструкции шейдера одновременно:

Для графического процессора с архитектурой SIMT инструкции сборки отличаются и становятся кодами инструкций, специфичными для SIMT:
: VEC8_sample vec_r0, vec_v4, t0, vec_s0 VEC8_mul vec_r3, vec_v0, cb0[0] VEC8_madd vec_r3, vec_v1, cb0[1], vec_r3 VEC8_madd vec_r3, vec_v2, cb0[2], vec_r3 VEC8_clmp vec_r3, vec_r3, l(0.0), l(1.0) VEC8_mul vec_o0, vec_r0, vec_r3 VEC8_mul vec_o1, vec_r1, vec_r3 VEC8_mul vec_o2, vec_r2, vec_r3 VEC8_mov o3, l(1.0)И контекст образует общую структуру с Ядром в качестве единицы, а несколько ALU одного Ядра совместно используют набор контекста:

Если имеется несколько ядер, в вычислении шейдера одновременно будут участвовать больше ALU. Данные, выполняемые каждым ядром, различны, это могут быть любые данные, такие как вершины, примитивы и пиксели:

4.6 Использование расширенных примеров
NV shader thread groupПредоставляет расширения OpenGL, которые могут запрашивать атрибуты, связанные с оборудованием, такие как потоки графического процессора, Core, SM и Warp. Если вы хотите открыть это расширение, вам необходимо выполнить следующие условия:
- OpenGL 4.3+;
- GLSL 4.3+;
- Видеокарта NV с поддержкой OpenGL 4.3+;
И это расширение работает только в шейдерах NV 5-го поколения:
This extension interacts with NV_gpu_program5
This extension interacts with NV_compute_program5
This extension interacts with NV_tessellation_program5Ниже приводится значение конкретных полей и представителей:
// открываем расширение #extension GL_NV_shader_thread_group : require (or enable) WARP_SIZE_NV // Количество потоков в одной основе WARPS_PER_SM_NV // Количество искривлений одного SM SM_COUNT_NV // номер SM uniform uint gl_WarpSizeNV; // количество нитей одной основы uniform uint gl_WarpsPerSMNV; // Деформирует номер одного SM uniform uint gl_SMCountNV; // счетчик SM in uint gl_WarpIDNV; // текущий идентификатор варпа in uint gl_SMIDNV; // Идентификатор SM, где находится текущий варп, значение [0, gl_SMCountNV-1] in uint gl_ThreadInWarpNV; // идентификатор текущего потока, значение [0, gl_WarpSizeNV-1] in uint gl_ThreadEqMaskNV; // Равно ли оно маске битового поля текущего идентификатора потока. in uint gl_ThreadGeMaskNV; // Больше или равно маске битового поля текущего идентификатора потока. in uint gl_ThreadGtMaskNV; // Больше, чем маска битового поля текущего идентификатора потока. in uint gl_ThreadLeMaskNV; // Она меньше или равна маске битового поля идентификатора текущего потока. in uint gl_ThreadLtMaskNV; // Меньше, чем маска битового поля текущего идентификатора потока. in bool gl_HelperThreadNV; // Является ли текущий поток вспомогательным.Вспомогательный поток gl_HelperThreadNV Означает, что при обработке блоков пикселей 2×2 те потоки пиксельного шейдера, которые не покрыты примитивами, будут помечены как gl_HelperThreadNV = true , Их результаты будут проигнорированы и не будут сохранены, но могут помочь в некоторых вычислениях, таких как производные dFdx с участием dFdy , Во избежание недоразумений разместите исходный текст:
The variable gl_HelperThreadNV specifies if the current thread is a helper thread. In implementations supporting this extension, fragment shader invocations may be arranged in SIMD thread groups of 2×2 fragments called «quad». When a fragment shader instruction is executed on a quad, it’s possible that some fragments within the quad will execute the instruction even if they are not covered by the primitive. Those threads are called helper threads. Their outputs will be discarded and they will not execute global store functions, but the intermediate values they compute can still be used by thread group sharing functions or by fragment derivative functions like dFdx and dFdy.
Используя указанные выше поля, вы можете написать специальный код шейдера и преобразовать его в информацию о цвете, чтобы визуально следить за рабочим механизмом и процессами графического процессора.

Используйте поле расширения NV для визуализации SM и Warp id вершинного шейдера и пиксельного шейдера, предоставляя нам возможность исследовать рабочий механизм и процесс графического процессора.
Следующее формально входит в фазу проверки. В качестве объекта проверки будет использоваться Geforce RTX 2060. Конкретная информация выглядит следующим образом:
Операционная система: Windows 10 Pro, 64-бит
Версия DirectX: 12.0
Графический процессор: GeForce RTX 2060
Версия драйвера: 417.71
Driver Type: Standard
Версия Direct3D API: 12
Уровень функции Direct3D: 12_1Ядро CUDA: 1920
Частота ядра: 1710 МГц
Скорость передачи данных памяти: 14,00 Гбит / с
Интерфейс памяти: 192-битный
Пропускная способность памяти: 336,05 ГБ / сек.
Вся доступная графическая память: 22494 МБ
Выделенная видеопамять: 6144 МБ GDDR6
Системная видеопамять: 0 МБ
Общая системная память: 16350 МБ
Версия видео BIOS: 90.06.3F.00.73
IRQ: Not used
Шина: PCI Express x16 Gen3Сначала создайте в приложении данные вершины, содержащие два треугольника:
// set up vertex data (and buffer(s)) and configure vertex attributes const float HalfSize = 1.0f; float vertices[] = < -HalfSize, -HalfSize, 0.0f, // left bottom HalfSize, -HalfSize, 0.0f, // right bottom -HalfSize, HalfSize, 0.0f, // top left -HalfSize, HalfSize, 0.0f, // top left HalfSize, -HalfSize, 0.0f, // right bottom HalfSize, HalfSize, 0.0f, // top right >;Вершинный шейдер, используемый для рендеринга, очень прост:
#version 430 core layout (location = 0) in vec3 aPos; void main()
Фрагментный шейдер — это тоже всего несколько строк:
#version 430 core out vec4 FragColor; void main()
Исходная нарисованная картинка выглядит следующим образом:

Затем измените фрагментный шейдер, добавьте код, необходимый для расширения, и измените расчет цвета:
#version 430 core #extension GL_NV_shader_thread_group : require uniform uint gl_WarpSizeNV; // количество нитей одной основы uniform uint gl_WarpsPerSMNV; // Деформирует номер одного SM uniform uint gl_SMCountNV; // счетчик SM in uint gl_WarpIDNV; // текущий идентификатор варпа in uint gl_SMIDNV; // Идентификатор SM, где находится текущий поток, значение [0, gl_SMCountNV-1] in uint gl_ThreadInWarpNV; // идентификатор текущего потока, значение [0, gl_WarpSizeNV-1] out vec4 FragColor; void main() < // SM id float lightness = gl_SMIDNV / gl_SMCountNV; FragColor = vec4(lightness); >Экран, отображаемый с помощью приведенного выше кода, выглядит следующим образом:

Некоторая информация может быть проанализирована из вышеизложенного:
- Всего на экране 32 уровня яркости, то есть Geforce RTX 2060 имеет 32 SM.
- Один SM визуализирует каждый раз блок размером 16×16 пикселей, то есть каждый SM имеет 256 ядер.
- Пиксельные блоки не распределяются между SM последовательно, а распределяются не по порядку.
- На стыках разных треугольников имеются дефекты, указывающие на то, что если один и тот же блок пикселей принадлежит разным треугольникам, он будет назначен для обработки разным SM. Сделайте вывод из этогоДля области с такой же площадью, чем большему количеству треугольников она принадлежит, тем больше раз она выделяется SM и тем большую производительность рендеринга он потребляет.。
Затем измените код расчета цвета фрагментного шейдера, чтобы отобразить идентификатор деформации:
// warp id float lightness = gl_WarpIDNV / gl_WarpsPerSMNV; FragColor = vec4(lightness);Получите следующий экран:

Из этого можно сделать некоторую информацию или выводы:
- На экране 32 уровня яркости, то есть каждый SM имеет 32 Warp, а каждый Warp имеет 8 ядер.
- Каждый пиксель цветового блока имеет размер 4×8, поскольку каждый Warp имеет 8 ядер, предполагается, что каждое ядро должно обрабатывать наименьший единичный блок пикселей 2×2 за раз.
- Он также распределяет блоки пикселей не по порядку.
- Имеется неисправность в треугольном соединении, что согласуется с выводом SM.
Затем измените код расчета цвета фрагментного шейдера, чтобы отобразить идентификатор потока:
// thread id float lightness = gl_ThreadInWarpNV / gl_WarpSizeNV; FragColor = vec4(lightness);Получите следующий экран:

Чтобы облегчить анализ, с помощью Photoshop увеличьте среднюю часть в 10 раз и получите следующую картинку:

Комбинируя две вышеупомянутые картинки, мы также можем сделать некоторые выводы:
- По сравнению с SM и warp диаграмма распределения нитей более правильная. Это показывает, что распределение потоков одного и того же Warp является регулярным.
- Нарушения в треугольных швах указывают на то, что разные основы вызывают разные нити.
- Экран имеет 32 уровня, что означает, что один Warp имеет 32 потока.
- Каждый пиксель имеет исключительный уровень яркости, который отличается от окружающих соседних пикселей, что означает, что каждый поток обрабатывает только один пиксель.
Опять же, приведенные выше изображения и выводы основаны на Geforce RTX 2060. Различные модели графических процессоров могут быть разными, и полученные результаты и выводы будут разными.
Другие расширения NV можно найти на официальном сайте OpenGL:NV extensions。
Пять, резюме
5.1 CPU vs GPU
Разницу между CPU и GPU можно описать в следующей таблице:
CPU GPU Допуск к задержке низкий высокая Параллельная цель задача Данные Основная архитектура Многопоточное ядро Ядро SIMT Уровень номера потока 10 10000 пропускная способность низкий высокая Требование кеша высокая низкий Независимость потоков низкий высокая Разницу между ними (кеш, количество ядер, память, количество потоков и т. Д.) Можно показать на следующем рисунке:

5.2 Предложения по оптимизации рендеринга
Из анализа, проведенного в предыдущей главе, можно легко дать предложения по оптимизации рендеринга:
- Уменьшите обмен данными между CPU и GPU:
- партия
- Уменьшите количество вершин и треугольников
- Обрезка ствола
- BVH
- Portal
- BSP
- OSP
- Версия частиц и анимации для ЦП будет изменяться и передавать данные каждый кадр, и ее можно перемещать на сторону ГП.
- Например: glGetUniformLocation Он будет запрашивать статус из памяти графического процессора, что занимает много времени.
- Избегайте установки и запроса состояния рендеринга в каждом кадре и кешируйте состояние во время инициализации.
- Избегайте операции Tex Kill
- Избегайте альфа-теста
- Избегайте альфа-смешения
- Открытый тест глубины
- Early-Z
- Иерархическая Z-буферизация (HZB)
- Назад вырез
- Окклюзионный урожай
- Обрезка области просмотра
- Ножничный прямоугольник
- Количество частиц велико, а площадь мала. Из-за механизма блокировки пикселей ситуация с перерисовкой будет усугубляться
- То же самое касается растений, песка, волос и т. Д.
- Избегайте операторов if и switch ветвления
- избегать for Операторы цикла, особенно с переменным временем цикла
- Уменьшите количество образцов текстуры
- Отключить clip или discard операционная
- Уменьшите количество вызовов сложных математических функций
Дополнительные советы по оптимизации можно прочитать:
- Общие методы оптимизации производительности мобильных игр。
- GPU Programming Guide。
- Real-Time Rendering Resources。
5.3 Будущее GPU
Из главы2.2 История GPUМожно сделать некоторые выводы, а также предположить тенденцию развития GPU:
- Апгрейд оборудования, Больше вычислительных единиц, больше места для хранения, больший параллелизм, большая пропускная способность и меньшая задержка. , ,
- Интеграция рендеринга на основе плитки, Рендеринг на основе плиток может снизить пропускную способность и до некоторой степени повысить эффективность расчета освещения.В настоящее время эта технология внедрена в некоторых мобильных и настольных графических процессорах, и ожидается, что в будущем она станет нормой.

- Технология 3D-памяти, В настоящее время наиболее традиционной памятью является двухмерная память, тогда как трехмерная память отличается от нее. Она имеет трехмерную физическую структуру, аналогичную кубической структуре, интегрированной в чип. Может получить в несколько раз большую скорость доступа и коэффициент полезного действия.

- GPU становится более программируемым, GPU по своей сути является параллельным и относительно фиксированным. В будущем для программирования будет доступно все больше и больше шейдеров, в то время как CPU — как раз наоборот и будет распараллеливаться. Другими словами, будущий графический процессор будет все больше и больше походить на ЦП, а ЦП будет все больше и больше походить на графический процессор. Исполнили ли они старую поговорку: если вы вместе долгое время, вы должны разделиться, а если вы разделитесь на долгое время, вы должны быть вместе?

- Популярность отслеживания света в реальном времени, В графические процессоры на основе архитектуры Тьюринга добавлено большое количество технологий, таких как RT Core, HVB и шумоподавление AI.Hybrid Rendering PipelineЭто конвейер рендеринга с трассировкой лучей этой архитектуры, который может одновременно выполнять гибридный рендеринг в сочетании с растеризатором, RT Core и Compute Core:
 Конвейер гибридной визуализации эквивалентен комбинации конвейера визуализации с трассировкой лучей и конвейера рендеринга растеризации:
Конвейер гибридной визуализации эквивалентен комбинации конвейера визуализации с трассировкой лучей и конвейера рендеринга растеризации: 
- Популяризация и улучшение параллелизма данных, глубоких нейронных сетей, вычислительных блоков GPU и т. Д.。

- Подавление шума AI и сглаживание AI, Подавление шума AI было применено в некоторых версиях трассировки лучей серии RTX, а сглаживание AI (Super Res) можно использовать для сглаживания видеоизображения сверхвысокого разрешения:

- Конвейер рендеринга на основе задачи и шейдера сетки, Графический конвейер с задачами и шейдерами сетки (Graphics Pipeline with Task and Mesh Shaders) сильно отличается от традиционного растеризованного освещения для визуализации. Он использует группу потоков, шейдер задач и сетку. На основе шейдера Mesh формируется новый конвейер рендеринга:
 Подробнее об этой технологии можно прочитать:NVIDIA Turing Architecture Whitepaper。
Подробнее об этой технологии можно прочитать:NVIDIA Turing Architecture Whitepaper。 - Затенение с переменной скоростью, Технология окрашивания с переменной скоростью может определять важность области изображения (или заданную приложением), а затем использовать различную точность разрешения окраски в соответствии с важностью области изображения, что может значительно снизить энергопотребление и повысить эффективность окраски.

5.4 Заключение
В этой статье систематически объясняется история, развитие, рабочий процесс графического процессора, а также дается подробное описание некоторых процессов и различных используемых технологий, из которых мы можем увидеть мотивы, механизмы, узкие места и будущее развитие архитектуры графического процессора.
Надеюсь, что после прочтения этой статьи каждый сможет хорошо ответить на вопросы, поднятые во введении:1.3 Читать с вопросами, Если вы не можете ответить на все из них, это не имеет значения. Оглядываясь на соответствующие главы, вы всегда можете найти ответ.
Если вы хотите глубже понять детали конструкции и реализации графических процессоров, вы можете прочитать официальные документы, регулярно выпускаемые производителями графических процессоров, и статьи, выпускаемые крупными университетами и учреждениями. Порекомендуйте видео с объяснением графического процессора:A trip through the Graphics Pipeline 2011: IndexХотя это видео, снятое много лет назад, оно систематически и всесторонне объясняет механизм и технологию GPU.
Специальная записка
- Спасибо всем авторам ссылок!
- Оригинальные статьи, перепечатка без разрешения запрещена!
Ссылки
- Real-Time Rendering Resources
- Life of a triangle — NVIDIA’s logical pipeline
- NVIDIA Pascal Architecture Whitepaper
- NVIDIA Turing Architecture Whitepaper
- Pomegranate: A Fully Scalable Graphics Architecture
- Performance Optimization Guidelines and the GPU Architecture behind them
- A trip through the Graphics Pipeline 2011
- Graphic Architecture introduction and analysis
- Exploring the GPU Architecture
- Introduction to GPU Architecture
- An Introduction to Modern GPU Architecture
- GPU TECHNOLOGY: PAST, PRESENT, FUTURE
- GPU Computing & Architectures
- NVIDIA VOLTA
- NVIDIA TURING
- Graphics processing unit
- Параллельная архитектура GPU и оптимизация рендеринга
- Оптимизация рендеринга — начиная со структуры GPU
- GPU Architecture and Models
- Introduction to and History of GPU Algorithms
- GPU Architecture Overview
- Компьютерные вещи (8) — принцип рендеринга графики и изображений
- GPU Programming Guide GeForce 8 and 9 Series
- Как работает GPU
- Список ядер дисплея NVIDIA
- DirectX
- Язык шейдеров высокого уровня
- Изучите технологию трассировки лучей и реализацию UE4
- Общие методы оптимизации производительности мобильных игр
- NV shader thread group
- Углубленное исследование рендеринга в реальном времени
- Введение в аппаратное обеспечение NVIDIA GPU
- Data Transfer Matters for GPU Computing
- Slang – A Shader Compilation System
- Graphics Shaders — Theory and Practice 2nd Edition
Можно ли подключать видеокарту AMD Radeon на компьютере Intel
Можно ли использовать графические процессоры AMD с процессорами Intel? Есть ли причина, по которой вы не должны этого делать или когда это полезно?
Давайте углубимся в эти вопросы вместе, и к концу статьи у вас должно быть чёткое представление о том, является ли комбинация AMD + Intel надёжной.

Совместимы ли графические процессоры AMD с процессорами Intel
Прежде всего, давайте установим основы: вы легко можете использовать графический процессор AMD с процессором Intel.
Две компании могут конкурировать как в области создания процессоров, так и видеокарт, но это не означает, что они не будут работать вместе внутри сборки вашего ПК.
Тем не менее, у вас могут остаться проблемы с общей совместимостью.
Например, нет ли каких-либо преимуществ, которые вы можете упустить, если не будете сочетать видеокарты AMD с процессорами AMD?
Преимущества использования видеокарт AMD вместе с процессором AMD
Память AMD Smart Access Memory (SAM) и Resizable BAR
Одной из примечательных особенностей видеокарт AMD в сочетании с процессорами AMD является функция под названием AMD Smart Access Memory .
По сути, AMD Smart Access Memory предоставляет ЦП больший доступ к видеопамяти, обеспечивая небольшой прирост производительности (~4% или меньше в большинстве случаев, 10% или более в редких случаях) в играх, что приятно, но вряд ли является обязательным для хорошего опыта.
Чего люди могут не знать, так это того, что это основано на функции под названием Resizable BAR (регистр базового адреса), которая не является специфичной для AMD.
На самом деле, многие процессоры Intel поддерживают использование Resizable BAR вместе с видеокартами AMD.
Следовательно, большая часть функций AMD/AMD прекрасно работает с установкой AMD/Intel. Есть ли какие-либо другие эксклюзивные функции комбинации процессора и видеокарты, о которых стоит беспокоиться?
Не совсем.
Ближе всего к этому раньше было что-то под названием AMD Dual Graphics, которое позволяло APU AMD (процессоры со встроенными графическими чипами) работать в режиме двух графических процессоров с некоторыми дискретными видеокартами AMD.
Однако, эта функция была довольно быстро исключена и больше не используется для текущих процессоров и видеокарт AMD.
Почему видеокарты AMD с процессорами Intel могут быть идеальной парой
Видеокарты AMD с процессорами Intel могут быть привлекательным сочетанием для одного типа пользователей, в частности: геймеров.
Современные процессоры Intel способны сохранять постоянное, хотя иногда и небольшое преимущество в игровой производительности по сравнению с процессорами AMD. Особенно для игр с высокой частотой обновления процессоры Intel могут показаться лучшим выбором для многих пользователей, даже если они используют видеокарты AMD.
Точно так же видеокарты AMD, как правило, имеют гораздо лучшую производительность на рубль в играх по сравнению с конкурирующими видеокартами.
Дополнительные деньги не обязательно тратятся впустую на Nvidia, особенно если вы или игры, в которые вы играете, могут эффективно использовать дополнительные аппаратные функции Nvidia, но если всё, что вам нужно, это стабильные кадры в секунду, видеокарты AMD могут быть лучшим компаньоном.
Когда выбрать видеокарту Nvidia для процессора Intel
Здесь есть слон в комнате, на которого следует обратить внимание, особенно если вы хотите использовать ускорение графического процессора для профессиональных и ориентированных на производительность рабочих нагрузок.
Когда дело доходит до неигрового использования, графические процессоры Nvidia значительно опережают видеокарты AMD во многих высокопроизводительных профессиональных рабочих нагрузках.
И в игровых, и в рабочих нагрузках графические процессоры AMD текущего поколения просто не могут конкурировать с графическими процессорами Nvidia, когда речь идёт о рабочих нагрузках трассировки лучей.
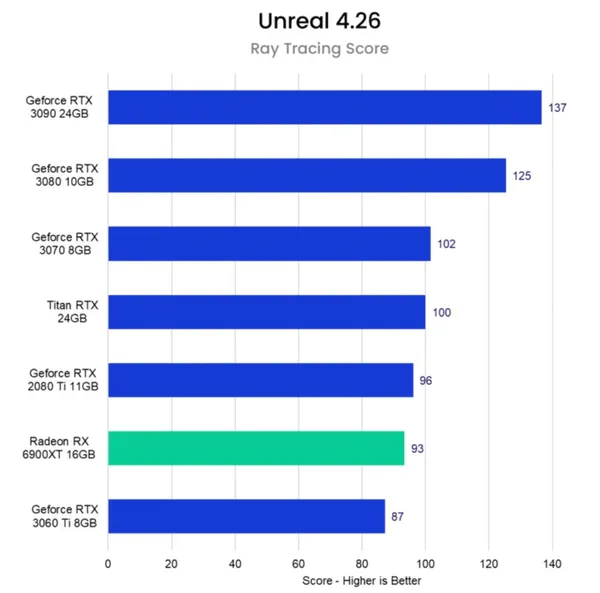
Если ваш игровой или профессиональный 3D-рендеринг требует большого количества трассировки лучей, AMD GPU может оказаться неправильным выбором для вашей сборки.
Особенно, если ваш 3D GPU Render Engine использует CUDA/OptiX для рендеринга, который поддерживается только на графических процессорах Nvidia!
Поэтому, если игры не являются вашим основным вариантом использования, возможно, не лучшая идея сочетать графический процессор AMD с процессором Intel.
Всё будет работать, но видеокарты Nvidia, как правило, лучше подходят для большинства тяжелых рабочих нагрузок, ориентированных на производительность.
Будут ли преимущества от соединия GPU Intel с CPU Intel
Возможно, нет.
Хотя я уверен, что после того, как эта конкретная комбинация выйдет на рынок, она будет предлагать некоторые интересные функции, но эти гипотетические улучшения не стоят того, чтобы сегодня откладывать жизнеспособную сборку персонального, игрового или рабочего ПК.
Например, помните упомянутую ранее функцию AMD Dual Graphics, которая позволяла AMD iGPU и AMD dGPU работать одновременно? Похоже, что Intel тоже этим занимается, но до тех пор, пока видеокарты Intel не выйдут на рынок, я бы не стал рассматривать их как возможность для апгрейда системы.
Кроме того, большинство технологий с несколькими графическими процессорами… не очень хорошо работают за пределами рабочих нагрузок, когда нагрузка на графический процессор может быть легко распределена между несколькими видеокартами, так что для игр это, вероятно, не будет иметь большого значения.
Часто задаваемые вопросы
Процессоры Intel лучше, чем процессоры AMD?
Как упоминалось выше, процессоры Intel стабильно лидируют в игровой производительности.
Тем не менее, эта корона производительности имеет тенденцию менять местами головы в каждом поколении, и часто процессоры AMD могут похвастаться невероятным лидерством в чистой многоядерной мощности процессора.
При правильном использовании эта мощность процессора может быть достаточно эффективно использована в таких вещах, как прямая трансляция и рендеринг/редактирование видео.
В конечном счёте, ответ на этот вопрос действительно будет зависеть от того, кто предлагает лучший продукт за ваши деньги в данном ценовом диапазоне и чьи функции вам нужны больше.
Это слишком общий вопрос, но если ваша главная или единственная забота – игровая производительность, у Intel небольшое преимущество.
Видеокарты Nvidia лучше, чем графические процессоры AMD?
Как упоминалось выше, графические процессоры AMD и Nvidia превосходны в разных вещах, но оба являются довольно солидными линейками продуктов сами по себе.
Если вас не беспокоят специфичные для оборудования функции Nvidia, то, как правило, разумно просто покупать у того крупного производителя, который предлагает вам лучшую сделку за ваши деньги в данном ценовом диапазоне.
Часто, особенно для геймеров, это AMD, но в других случаях Nvidia действительно может выдать приличное преимущество.
Тем не менее, перед принятием окончательного решения о покупке вы всегда стоит перепроверить тесты между конкурирующими видеокартами.
Каковы лучшие бренды графических процессоров?
Ещё один вопрос, который приходит на ум при покупке видеокарт, – у каких брендов или партнеров AIB покупать.
В то время как AMD и Nvidia производят базовые чипы для графических процессоров, их партнёры, как правило, имеют уникальные конструкции кулеров, которые можно потом установить поверх, и имеют различные уровни обслуживания клиентов и гарантии, о которых следует помнить.
CPU и GPU: как выбрать идеальную пару

Разбираемся, в функциях процессора и видеокарты и выясняем, как правильно сочетать мощность этих компонентов
Подбор идеального сочетания процессора и видеокарты – довольно сложный и ответственный момент, как при сборке ПК с нуля, так и при апгрейде системы. Сегодня мы поговорим о том, почему не стоит в пару к посредственному процессору ставить мощную видеокарту, и по каким критериям подбирать пары.
Почему не стоит сочетать слабые и сильные комплектующие?
В сети непросто найти информацию о соответствии видеокарт процессорам. Поэтому большинство покупок совершаются по наитию, совету друзей или исходя из мнения консультанта в магазине. Нередки случаи, когда одно из устройств тандема значительно отстает в производительности.
Здесь возможны два варианта:
- Мощности процессора при слабой видеокарте попросту простаивают. А вложение средств в дополнительные ядра оказывается пустой тратой денег.
- Слабый процессор не позволяет раскрыть весь потенциал видеокарты. К тому же нагрузка на процессор в такой сборке становится чрезмерной и может привести к перегреву и троттлингу.
Таким образом, главная особенность каждой компьютерной системы: производительность лимитируется слабейшим устройством в сборке. И не важно, что это за элемент – видеокарта, процессор, оперативная память или блок питания.
Если говорить о приложениях, то несбалансированная сборка может заметно повлиять на игровой процесс, вызвать подвисания и привести к падению FPS. А вот в рабочих сборках, в зависимости от вида деятельности, требования к сочетанию графического и центрального процессора могут отличаться. В этой сфере допускается сочетание многоядерного топового процессора с бюджетной видеокартой, как и наоборот: профессиональной видеокарты, например, линейки Quadro и бюджетного процессора на четыре ядра.
За что именно отвечают центральный и графический процессоры?
Сейчас мы говорим о пользовательских игровых комплектациях. А значит функциями CPU являются расчет параметров игрового мира, обработка геометрических параметров статичных и динамичных объектов, их движения, физики и деформации. Чем больше объектов присутствует в кадре, тем выше нагрузка на процессор. Если игра использует технологии искусственного интеллекта, то поддержка этой опции также ложится на процессор.
При этом степень загрузки центрального чипа не зависит от качества графики, детализации объектов, параметров света и отражения, фактур и свойств поверхностей. Также на процессорную нагрузку не влияет и выбранное пользователем разрешение картинки. Это значит, что если процессор показывает максимальную загрузку, а FPS не поднимается выше некомфортных 30 – 40 кадров, то настройкой разрешения картинки и качества изображения компьютеру не поможешь, разве что только изменением дальности прорисовки сцены.
Также, запуская игру, следует учитывать, что центральный чип в любой момент загружен не только игровым процессом, но и множеством параллельных, включая фоновые задачи и свернутые приложения. Поэтому незначительно повысить производительность можно предварительным отключением некоторых приложений. Обязательно перед игрой закрывайте браузер и мессенджеры. Также лучше не использовать медийный проигрыватель.
К задачам видеокарт относятся прорисовка текстур, создание теней, лучей, бликов, отражений. Другими словами – визуальных особенностей игровых объектов. Также видеокарта сглаживает углы и накладывает на объекты различные эффекты. Поэтому, уменьшение качества игровых настроек существенно облегчает работу видеокарты.
Как определить слабое звено?
Для этого понадобится любая программа, которая сможет выполнять мониторинг рабочих параметров компьютерных узлов и выводить результаты поверх игрового поля. Самая популярная – бесплатное приложение MSI Afterburner.
Понять какое устройство тормозит систему можно по уровню загрузки, которая демонстрируется в процентах. Просто сравните показатели в строках CPU и GPU и вам сразу станет понятно, какой узел загружен по максимуму и выступает лимитирующим фактором.
Как подобрать сбалансированную пару?
Многие годы собирая компьютер пользователи опирались на простую схему: в одной сборке видеокарта должна стоить в 2 раза больше процессора. Однако, начиная с середины 2020 года этот принцип утратил актуальность, поскольку из-за нехватки видеокарт они взлетели в стоимости в несколько раз.
Поэтому самым доступным способом станет деление устройств на категории:
К процессорам бюджетного сегмента следует подбирать младшие модели в линейках графических адаптеров. Например, по производительности друг другу соответствуют видеокарта GeForce GT 730 и микрочип Ryzen 3 1300Х. В итоге получим неплохую офисную сборку без игрового потенциала.
А вот видеокарты младше брать не советуем. Например, уровень производительности GeForce GT 710 настолько низок, что встроенные в процессор графические ядра показывают результаты куда лучше. Так что оптимальным вариантом будет покупка процессора со встроенной графикой, чем процессор без графического ядра и видеокарту GT 710. Однако, свои роли есть и у такой слабой карты. Она способна заменить вышедшую из строя дискретную видеокарту на время ремонта или позволить подключить мониторы, если в системном блоке нет видеокарты вообще.
Средние модели в линейках позволят поиграть в нетребовательные игры или приложения посложнее, он на минимальных настройках. В качестве примера можно назвать видеокарту Radeon RX 550 и Core i7-7700K.
Хорошая игровая сборка получится при сочетании процессоров Core i5-10400F или его конкурента Ryzen 5 3600 с графическим адаптером GeForce GTX 1660 Ti.
А вот для игры на максимальных настройках необходимы флагманские модели. Например, топовые восьмиядерные процессоры от Intel демонстрируют максимум производительности с видеокартами Radeon RX 6700 XT, GeForce RTX 3070 и GeForce RTX 3070 Ti.
Также можно воспользоваться таблицами совместимости, которые широко распространены в сети. При выборе сбалансированной пары графического и центрального процессоров обязательно проверьте информацию по нескольким источникам. Пары могут существенно отличаться и нет никаких гарантий, что вам попались достоверные данные. Однако в большинстве случаев выбор ограничивается наличием товаров в магазине, сейчас это утверждение особенно актуально в отношении видеокарт.
- Все посты
- KVM-оборудование (equipment) (2)
- Powerline-адаптеры (2)
- Безопасность (security) (4)
- Беспроводные адаптеры (4)
- Блоки питания (power supply) (12)
- Видеокарты (videocard) (43)
- Видеонаблюдение (CCTV) (6)
- Диски HDD и твердотельные SSD (60)
- Дисковые полки (JBOD) (2)
- Звуковые карты (sound card) (3)
- Инструменты (instruments) (1)
- Источники бесперебойного питания (ИБП, UPS) (26)
- Кабели и патч-корды (5)
- Коммутаторы (switches) (13)
- Компьютерная периферия (computer peripherals) (42)
- Компьютеры (PC) (42)
- Контроллеры (RAID, HBA, Expander) (4)
- Корпусы для ПК (13)
- Материнские платы для ПК (27)
- Многофункциональные устройства (МФУ) (6)
- Модули памяти для ПК, ноутбуков и серверов (16)
- Мониторы (monitor) (36)
- Моноблоки (All-in-one PC) (8)
- Настольные системы хранения данных (NAS) (2)
- Ноутбуки (notebook, laptop) (34)
- Общая справка (46)
- Охлаждение (cooling) (16)
- Планшеты (tablets) (3)
- Плоттеры (plotter) (1)
- Принтеры (printer) (6)
- Программное обеспечение (software) (41)
- Программное обеспечение для корпоративного потребителя (15)
- Проекторы (projector) (2)
- Процессоры для ПК и серверов (45)
- Рабочие станции (workstation) (5)
- Распределение питания (PDU) (1)
- Расходные материалы для оргтехники (1)
- Расширители Wi-Fi (повторители, репиторы) (3)
- Роутеры (маршрутизаторы) (14)
- Серверы и серверное оборудование (42)
- Сетевые карты (network card) (4)
- Сетевые фильтры (surge protector) (2)
- Системы хранения (NAS) (1)
- Сканеры (scanner) (1)
- Телекоммуникационные шкафы и стойки (6)
- Телефония (phone) (4)
- Тонкие клиенты (thin client) (2)
- Трансиверы (trensceiver) (5)
- Умные часы (watch) (1)
Также вас может заинтересовать
Источник https://russianblogs.com/article/8488790507/
Источник https://webznam.ru/blog/amd_radeon_na_intel/2022-10-02-2147
Источник https://andpro.ru/blog/pc/cpu-i-gpu-kak-vybrat-idealnuyu-paru/
- мозаика